
Uso de RAG (Generación Aumentada por Recuperación) en modelos open source
La generación mejorada por recuperación (RAG) es el proceso de optimización de la salida de un modelo lingüístico de gran tamaño, de modo que haga referencia a una base de conocimientos autorizada fuera de los orígenes de datos de entrenamiento antes de generar una respuesta. Los modelos de lenguaje de gran tamaño (LLM) se entrenan con grandes volúmenes de datos y usan miles de millones de parámetros para generar resultados originales en tareas como responder preguntas, traducir idiomas y completar frases. RAG extiende las ya poderosas capacidades de los LLM a dominios específicos o a la base de conocimientos interna de una organización, todo ello sin la necesidad de volver a entrenar el modelo. Se trata de un método rentable para mejorar los resultados de los LLM de modo que sigan siendo relevantes, precisos y útiles en diversos contextos.
- Para tener más información te recomiendo visites el siguiente artículo de AWS.
- También en este artículo se explica de una forma más técnica.
A continuación se muestran las fases de la técnica RAG:
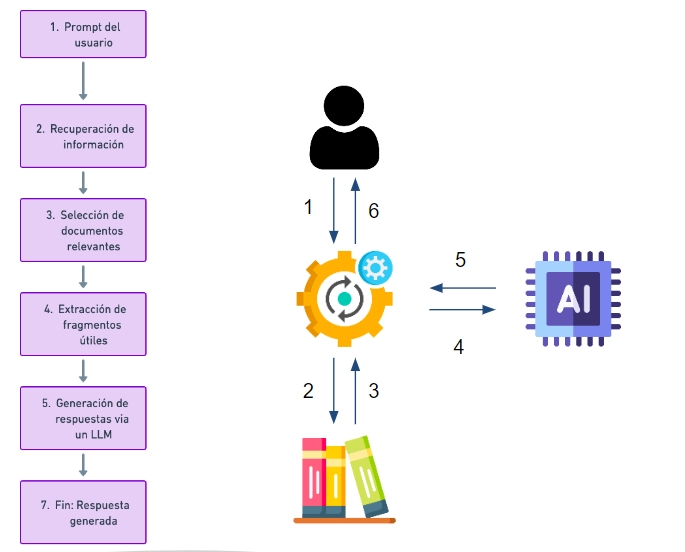
Repositorio con el contenido
RAG Mistral model

RAG RoBERTa model
Fuentes:
- https://aws.amazon.com/es/what-is/retrieval-augmented-generation/
- https://www.thepowerplatformcave.com/rag-ia-generativa-con-tus-datos/
- https://observatorio-ia.com/wp-content/uploads/2024/02/RAG.png
- https://www.e2enetworks.com/blog/implementing-a-rag-pipeline-with-mixtral-8x7b
- https://www.hiberus.com/crecemos-contigo/ask-your-web-pages-otro-enfoque-rag-utilizando-modelos-de-codigo-abierto/
- https://www.datacamp.com/tutorial/mistral-7b-tutorial
- https://haystack.deepset.ai/tutorials/22_pipeline_with_promptnode